Si estas empezando en Data Science, tarde o temprano vas a necesitar SQL. No es opcional. La mayoría de los datos del mundo real viven en bases de datos relacionales, y SQL es el idioma para hablar con ellas.
En está guía te llevo desde cero hasta un nivel sólido: lo suficiente para extraer datos, hacer análisis y resolver preguntas reales en entrevistas técnicas.
Por qué SQL es fundamental para Data Science
Python y R son geniales, pero antes de analizar datos necesitas obtenerlos. Y en la mayoría de empresas, eso significa escribir queries SQL contra una base de datos.
- Es el lenguaje más usado para acceder a datos en empresas
- Aparece en casi todas las ofertas de trabajo de Data Analyst y Data Scientist
- Te permite hacer análisis directamente en la base de datos sin descargar nada
- Es la base para herramientas como BigQuery, Redshift, Snowflake y dbt
- Es más fácil de aprender de lo que parece
SELECT, FROM y WHERE: la base de todo
Toda query SQL empieza con lo mismo: qué columnas quieres (SELECT), de que tabla (FROM) y con que filtros (WHERE).
-- Seleccionar todas las columnas
SELECT *
FROM clientes;
-- Seleccionar columnas específicas con filtro
SELECT nombre, email, ciudad
FROM clientes
WHERE ciudad = 'Madrid';
-- Filtros combinados
SELECT nombre, edad, plan
FROM clientes
WHERE edad >= 25
AND plan = 'premium'
AND fecha_registro >= '2025-01-01';Consejo: evita SELECT * en producción. Siempre especifica las columnas qué necesitas. Es más rápido y más claro.
ORDER BY y LIMIT: ordenar y limitar resultados
-- Los 10 clientes más recientes
SELECT nombre, fecha_registro
FROM clientes
ORDER BY fecha_registro DESC
LIMIT 10;
-- Productos más caros
SELECT nombre, precio
FROM productos
WHERE categoría = 'electrónica'
ORDER BY precio DESC
LIMIT 5;Funciones de agregación y GROUP BY
GROUP BY es donde SQL empieza a parecerse al análisis de datos de verdad. Te permite agrupar filas y calcular estadísticas por grupo.
-- Total de ventas por ciudad
SELECT ciudad, COUNT(*) AS total_ventas, SUM(monto) AS ingresos
FROM ventas
GROUP BY ciudad
ORDER BY ingresos DESC;
-- Promedio de compra por categoría
SELECT categoría,
AVG(monto) AS ticket_promedio,
MIN(monto) AS compra_minima,
MAX(monto) AS compra_maxima
FROM ventas
GROUP BY categoría;
-- Filtrar grupos con HAVING
SELECT ciudad, COUNT(*) AS total_ventas
FROM ventas
GROUP BY ciudad
HAVING COUNT(*) > 100
ORDER BY total_ventas DESC;La diferencia entre WHERE y HAVING: WHERE filtra filas antes de agrupar, HAVING filtra grupos después de agrupar.
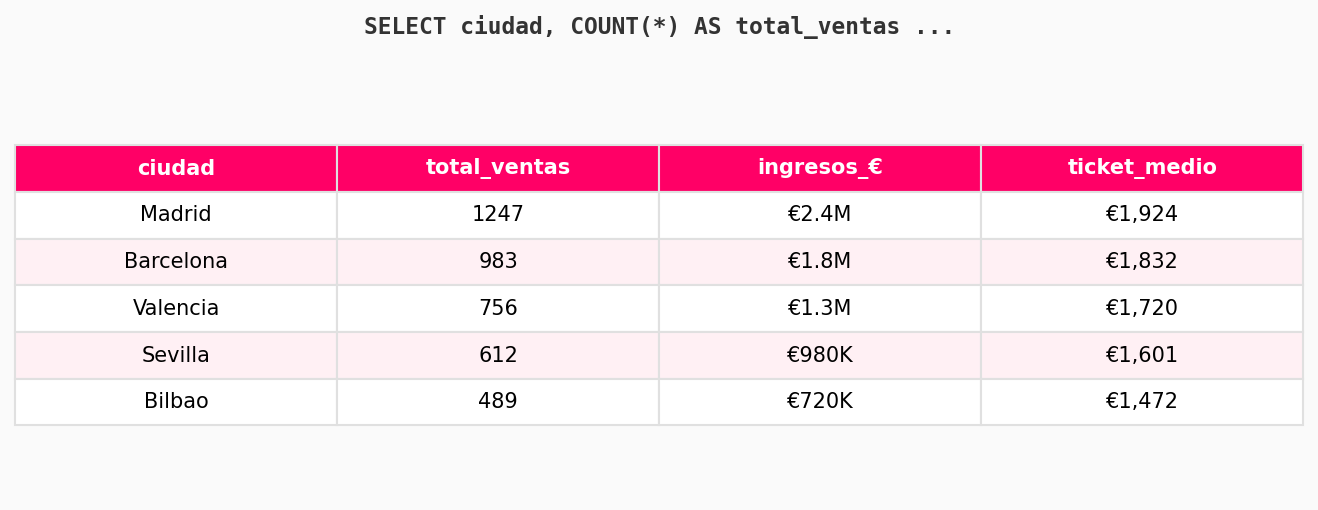
JOINs: combinar tablas
En bases de datos reales, la información está repartida en varias tablas. Los JOINs te permiten combinarlas.
-- INNER JOIN: solo filas que coinciden en ambas tablas
SELECT c.nombre, c.email, v.monto, v.fecha
FROM clientes c
INNER JOIN ventas v ON c.id = v.cliente_id;
-- LEFT JOIN: todos los clientes, aunque no tengan ventas
SELECT c.nombre, COUNT(v.id) AS total_compras
FROM clientes c
LEFT JOIN ventas v ON c.id = v.cliente_id
GROUP BY c.nombre
ORDER BY total_compras DESC;
-- Unir tres tablas
SELECT c.nombre, p.nombre AS producto, v.monto
FROM ventas v
INNER JOIN clientes c ON v.cliente_id = c.id
INNER JOIN productos p ON v.producto_id = p.id
WHERE v.fecha >= '2026-01-01';El tipo de JOIN más común en Data Science es LEFT JOIN, porque normalmente quieres mantener todos los registros de tu tabla principal aunque no tengan match en la otra.
Subqueries: queries dentro de queries
A veces necesitas el resultado de una query para filtrar otra. Ahi entran las subqueries.
-- Clientes que gastaron más que el promedio
SELECT nombre, total_gastado
FROM (
SELECT c.nombre, SUM(v.monto) AS total_gastado
FROM clientes c
INNER JOIN ventas v ON c.id = v.cliente_id
GROUP BY c.nombre
) AS resumen
WHERE total_gastado > (SELECT AVG(monto) FROM ventas);
-- Productos que nunca se vendieron
SELECT nombre
FROM productos
WHERE id NOT IN (
SELECT DISTINCT producto_id
FROM ventas
);Las subqueries son útiles pero pueden volverse difíciles de leer. Si una subquery se complica, considera usar CTEs (Common Table Expressions).
-- Lo mismo pero con CTE (más legible)
WITH resumen_clientes AS (
SELECT c.nombre, SUM(v.monto) AS total_gastado
FROM clientes c
INNER JOIN ventas v ON c.id = v.cliente_id
GROUP BY c.nombre
)
SELECT nombre, total_gastado
FROM resumen_clientes
WHERE total_gastado > (SELECT AVG(monto) FROM ventas)
ORDER BY total_gastado DESC;Window functions: análisis avanzado
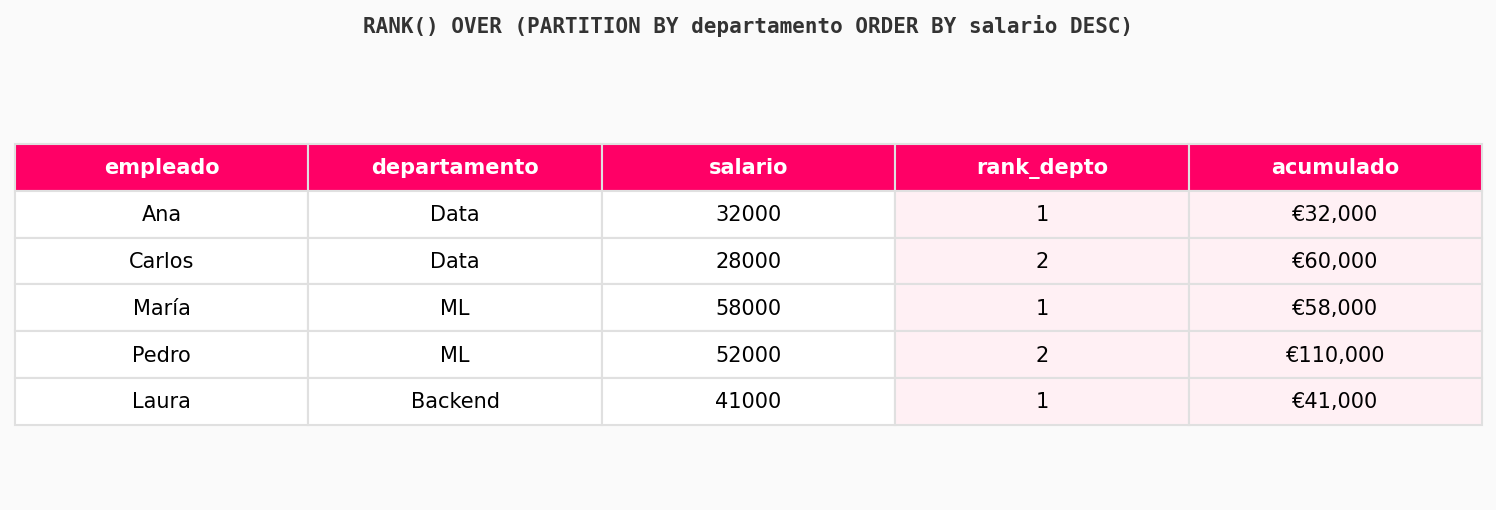
Las window functions son el nivel que separa a un usuario básico de SQL de alguien que realmente sabe analizar datos. Te permiten hacer cálculos sobre un grupo de filas sin perder el detalle individual.
-- Ranking de clientes por gasto total
SELECT nombre, total_gastado,
RANK() OVER (ORDER BY total_gastado DESC) AS ranking
FROM (
SELECT c.nombre, SUM(v.monto) AS total_gastado
FROM clientes c
INNER JOIN ventas v ON c.id = v.cliente_id
GROUP BY c.nombre
) AS resumen;
-- Ventas acumuladas por mes
SELECT fecha, monto,
SUM(monto) OVER (ORDER BY fecha) AS acumulado
FROM ventas;
-- Comparar cada venta con el promedio de su categoría
SELECT producto, categoría, monto,
AVG(monto) OVER (PARTITION BY categoría) AS promedio_categoria,
monto - AVG(monto) OVER (PARTITION BY categoría) AS diferencia
FROM ventas;Las window functions más útiles para Data Science son: ROW_NUMBER(), RANK(), LAG(), LEAD(), SUM() OVER y AVG() OVER.
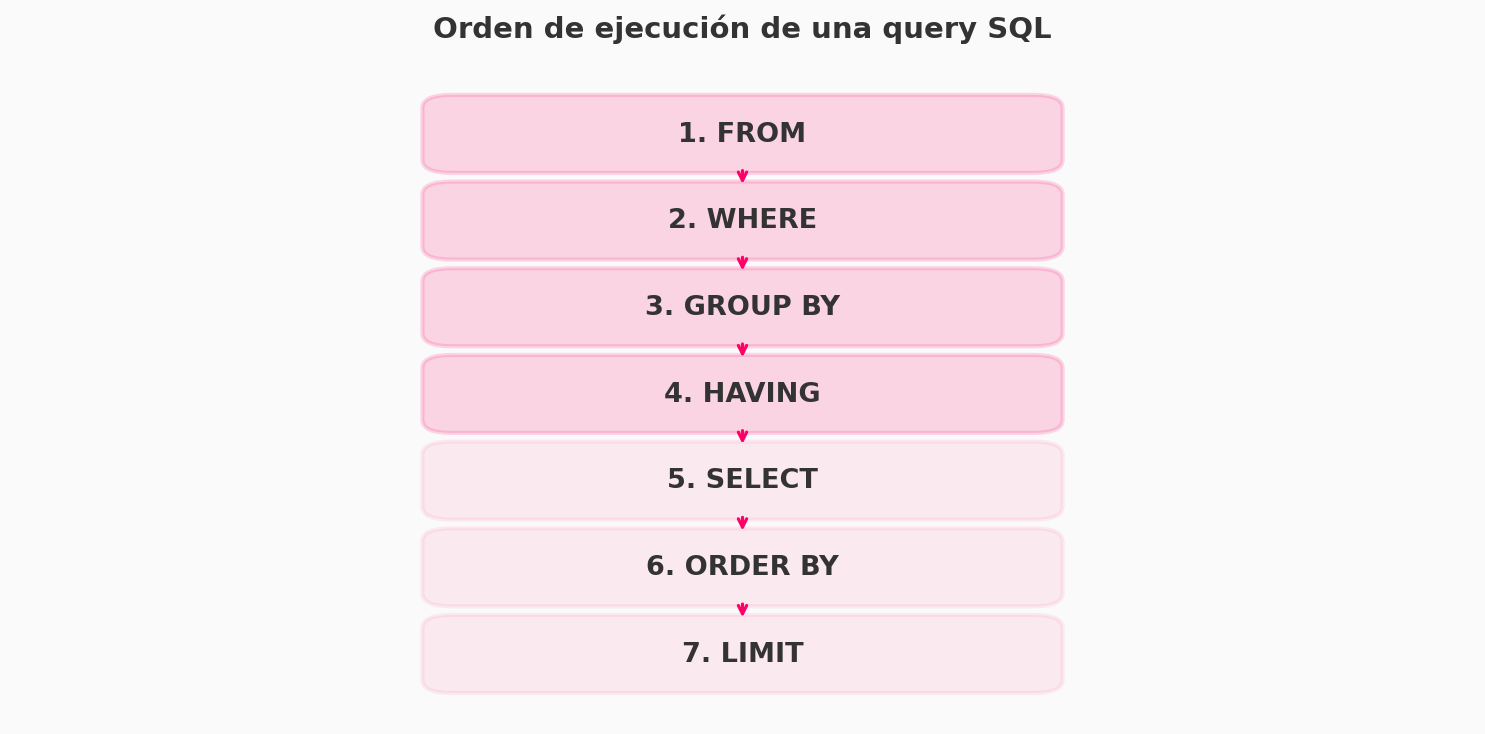
Orden de ejecución de una query SQL
Esto es clave para entender por qué algunas cosas funcionan y otras no. SQL no se ejecuta en el orden en que lo escribes:
FROMyJOIN- de dónde sacas los datosWHERE- filtras filasGROUP BY- agrupasHAVING- filtras gruposSELECT- eliges columnasORDER BY- ordenasLIMIT- limitas resultados
Por eso no puedes usar un alias de SELECT en el WHERE: el WHERE se ejecuta antes que el SELECT.
Recursos para practicar
- SQLBolt - Ejercicios interactivos ideales para empezar desde cero
- Mode Analytics SQL Tutorial - Muy bueno para practicar con datos reales
- LeetCode (sección SQL) - Problemas tipo entrevista técnica
- HackerRank SQL - Ejercicios progresivos por dificultad
- PostgreSQL - Instala una base de datos local y práctica con tus propios datos
- BigQuery Sandbox - Gratis, con datasets públicos enormes para explorar
Mi recomendación: empieza con SQLBolt para los fundamentos, pasa a LeetCode para queries más complejas, y práctica con datos reales en BigQuery. La clave es escribir queries todos los días, aunque sean 15 minutos.