Cuando empecé a aprender Python para análisis de datos, cometí el error de intentar aprenderlo todo. Clases, decoradores, programación orientada a objetos... cosas que están bien pero que no necesitas para analizar datos.
Aquí te cuento exactamente qué necesitas aprender, en qué orden, y qué puedes ignorar por ahora.
Lo que SI necesitas: Python básico (semana 1-2)
Variables y tipos de datos
nombre = "aroaxinping" # string
edad = 23 # int
nota_media = 8.5 # float
activa = True # booleanListas y diccionarios
# Lista: coleccion ordenada
herramientas = ["Python", "SQL", "Pandas", "Tableau"]
herramientas[0] # "Python"
len(herramientas) # 4
# Diccionario: clave-valor
alumna = {
"nombre": "Aroa",
"area": "Data Science",
"horas_estudio": 348
}
alumna["area"] # "Data Science"Bucles y condicionales
# For loop
for h in herramientas:
print(f"Estoy aprendiendo {h}")
# Condicional
if nota_media >= 8:
print("Buen promedio")
else:
print("A seguir estudiando")Funciones básicas
def calcular_porcentaje(parte, total):
return round((parte / total) * 100, 2)
calcular_porcentaje(847, 1000) # 84.7Lo que DE VERDAD usas: Pandas (semana 3-6)
Pandas es la librería más importante para análisis de datos en Python. El 80% de tu tiempo con datos lo pasas aquí.
Cargar datos
import pandas as pd
df = pd.read_csv('ventas.csv')
df = pd.read_excel('datos.xlsx')
df.head() # primeras 5 filas
df.shape # (filas, columnas)
df.info() # tipos y nulos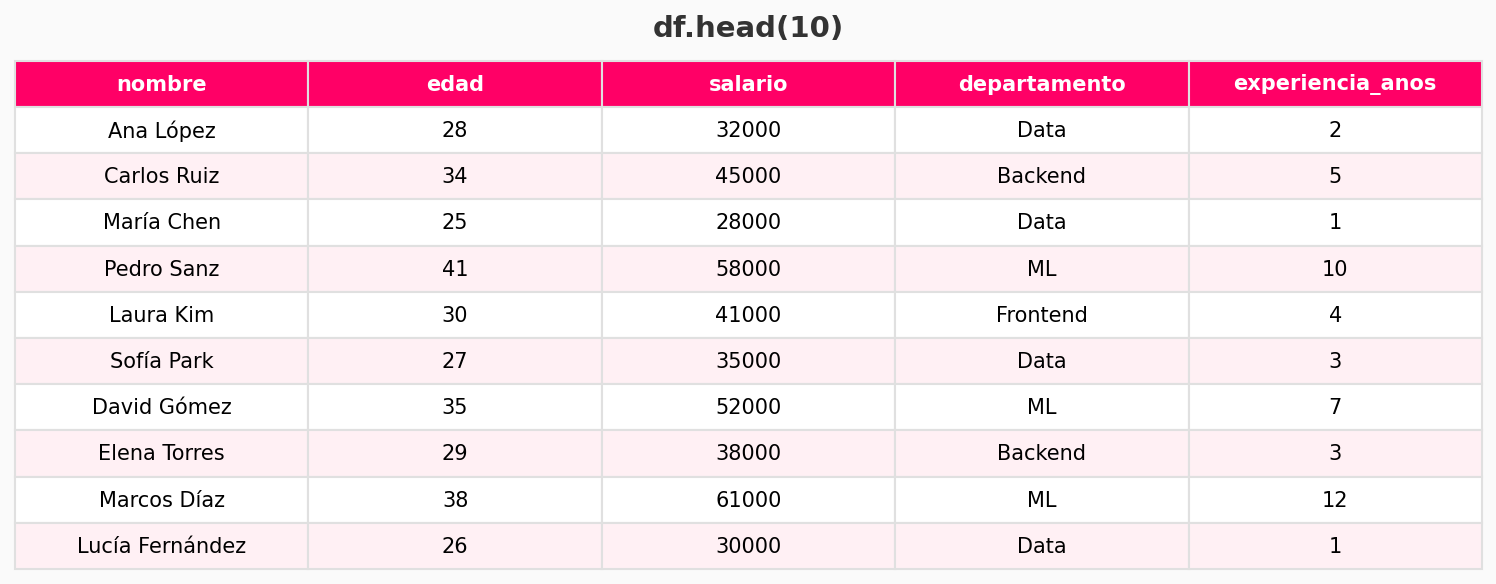
Filtrar y seleccionar
# Seleccionar columnas
df['precio']
df[['nombre', 'precio']]
# Filtrar filas
df[df['precio'] > 100]
df[df['categoría'] == 'Electronica']
df[(df['precio'] > 50) & (df['stock'] > 0)]Agrupar y resumir
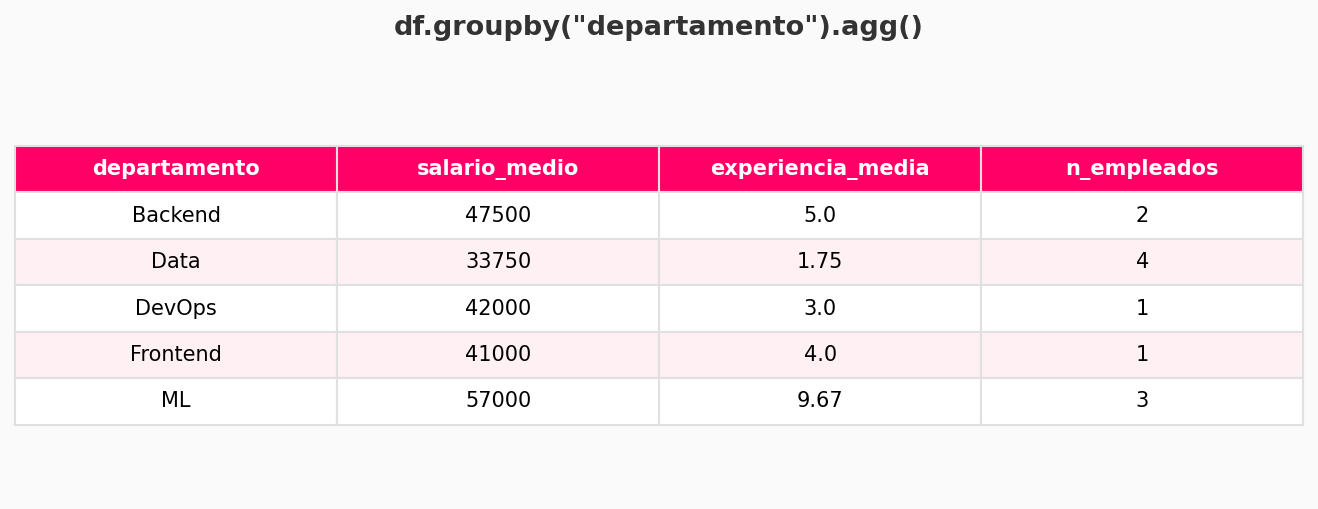
# Ventas totales por categoría
df.groupby('categoría')['ventas'].sum()
# Media de precio por región
df.groupby('región')['precio'].mean()
# Multiples operaciones
df.groupby('categoría').agg({
'ventas': 'sum',
'precio': 'mean',
'producto': 'count'
})
Limpiar datos
# Valores nulos
df.isnull().sum()
df.fillna(0) # rellenar con 0
df.dropna() # eliminar filas con nulos
# Duplicados
df.drop_duplicates()
# Cambiar tipos
df['fecha'] = pd.to_datetime(df['fecha'])Visualización básica: Matplotlib + Seaborn (semana 5-7)
import matplotlib.pyplot as plt
import seaborn as sns
# Gráfico de barras
df['categoría'].value_counts().plot(kind='bar', color='#d4738a')
plt.title('Productos por categoría')
plt.show()
# Histograma
sns.histplot(df['precio'], bins=30, color='#d4738a')
plt.title('Distribución de precios')
plt.show()
# Scatter plot
sns.scatterplot(data=df, x='precio', y='ventas', hue='categoría')
plt.show()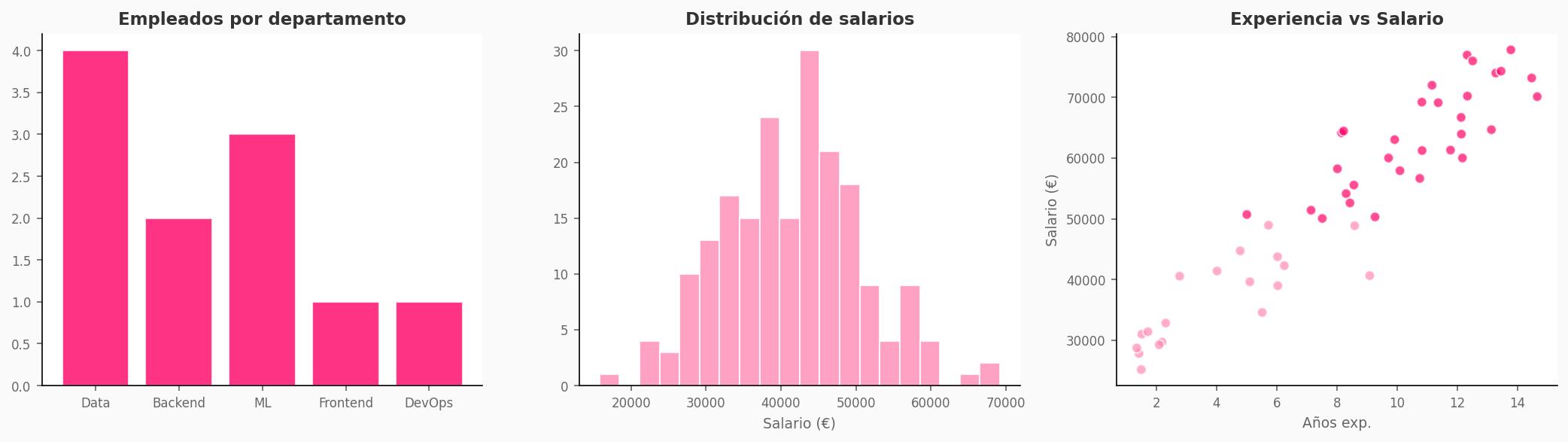
Lo qué puedes IGNORAR por ahora
- Programación orientada a objetos (clases): no la necesitas para analizar datos
- Decoradores y generadores: avanzado, no es prioritario
- Desarrollo web (Django, Flask): otro mundo completamente diferente
- Algoritmos y estructuras de datos: útil para entrevistas, pero no para empezar
- Asyncio/threading: no lo vas a necesitar en análisis de datos
Mi rutina de estudio
- 30 min de teoría (video o lectura)
- 1 hora de práctica con un dataset real
- Apuntar lo que no entiendo y buscarlo al día siguiente
La clave es practicar con datos reales desde el primer día. No esperes a "terminar el curso" para tocar un CSV.
Dónde practicar gratis
- Google Colab: notebook en la nube, sin instalar nada
- Kaggle: datasets gratuitos + notebooks de otros para aprender
- freeCodeCamp: curso de análisis de datos con Python en español
- datos.gob.es: datos abiertos del gobierno de España