Cuando empecé a estudiar data science, pensaba que el trabajo era hacer modelos y gráficos bonitos. Nadie me dijo que el 80% del tiempo lo iba a pasar limpiando datos.
Y no es broma. Los datasets reales son un desastre. Valores nulos por todos lados, columnas con formatos mixtos, duplicados que no parecen duplicados, y fechas en 14 formatos diferentes.
Mi checklist de limpieza con Pandas
Después de varios EDAs, ya tengo una rutina que sigo siempre:
1. Primera mirada
df.shape
df.info()
df.describe()
df.head(10)
Con esto ya se cuántas filas tengo, qué tipos de datos hay, y si hay algo raro a simple vista.
2. Valores nulos
df.isnull().sum()
df.isnull().mean() * 100 # porcentaje de nulos por columnaSi una columna tiene más del 50% de nulos, probablemente la elimino. Si tiene pocos, decido entre rellenar con la media/mediana o eliminar las filas.
3. Duplicados
df.duplicated().sum()
df[df.duplicated(keep=False)] # ver todos los duplicadosOjo: a veces los duplicados son legítimos (dos compras iguales en el mismo día). Hay que entender el contexto antes de borrar.
4. Tipos de datos
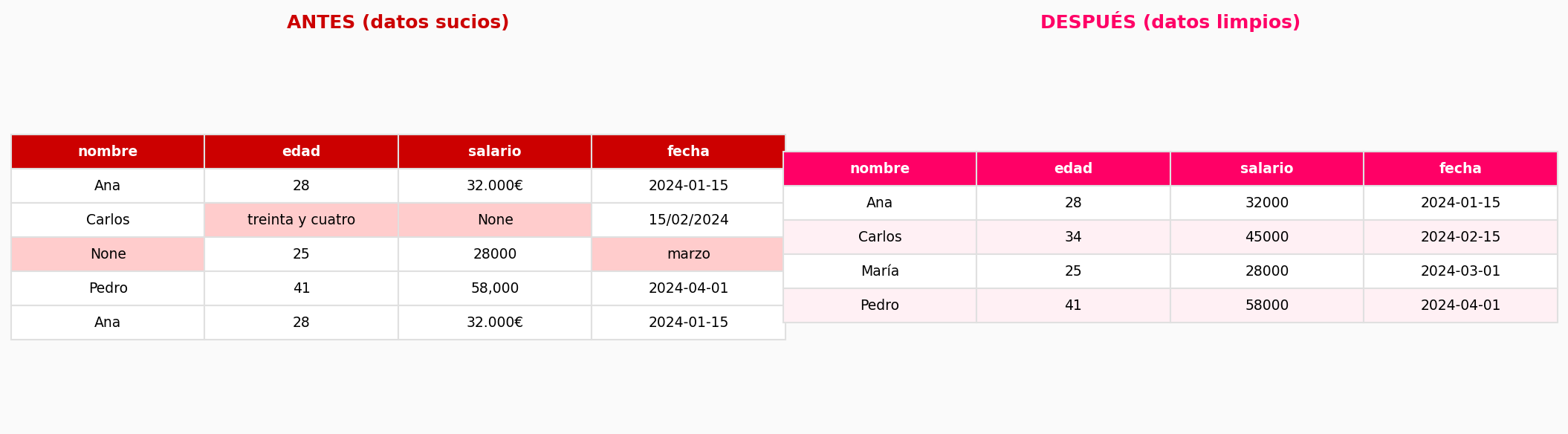
# Columna que debería ser fecha pero es string
df['fecha'] = pd.to_datetime(df['fecha'], format='%d/%m/%Y')
# Columna numérica guardada como texto
df['precio'] = df['precio'].str.replace(',', '.').astype(float)5. Outliers
# Método IQR básico
Q1 = df['columna'].quantile(0.25)
Q3 = df['columna'].quantile(0.75)
IQR = Q3 - Q1
mask = (df['columna'] >= Q1 - 1.5*IQR) & (df['columna'] <= Q3 + 1.5*IQR)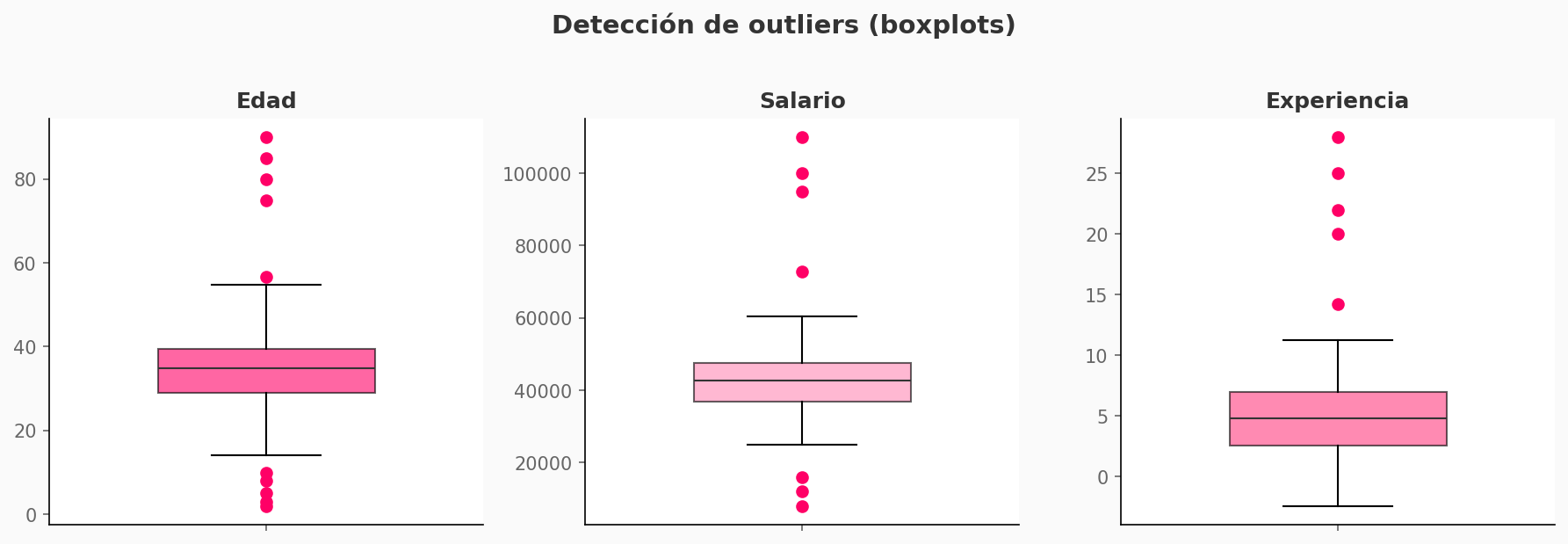
Errores que cometí al principio
- Borrar nulos sin pensar. A veces un nulo tiene significado (por ejemplo, "no aplica").
- No guardar el dataset original. Siempre hago
df_raw = df.copy()antes de tocar nada. - Limpiar antes de explorar. Primero hay que entender los datos. Luego limpiar.
Lo que nadie te dice
La limpieza de datos no es glamurosa, pero es donde se gana o se pierde un análisis. Un modelo con datos sucios da resultados sucios. No hay atajo.
Ahora cada vez que abro un CSV nuevo, lo primero que hago es respirar hondo y aceptar que voy a pasar un rato largo aquí. Y está bien.